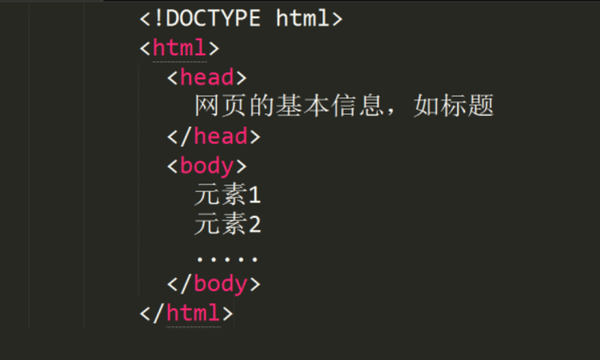
文章有标题、正文。同理,.html文件也有独特的结构——声明+元信息+内容:
4.它是如何跟浏览器沟通的?
HTML文件的每一部分,代表了浏览器解析文件所需的关键信息,方便浏览器能更好理解、准确解析:
A.<!DOCTYPE html>:声明文档类型。当浏览器解析HTML文件时,会先查找此声明,以确定用哪种方式渲染网站。此语句相当于告诉浏览器:这是一个HTML文档,请按HTML5的标准解析它。
B.<head></head>:描述网页的基础信息;如<title>标签定义的标题;<meta>标签定义的css样式表、js文件、编码方式等。这些信息帮助浏览器更好的理解页面,如<meta chartset=UTF-8>告诉浏览器应使用utf编码。
C.<body></body>:用若干个元素定义了用户在网页上看到的内容,如一张图、一段文字。元素中可以嵌套其他元素,使文件呈树状层级结构:
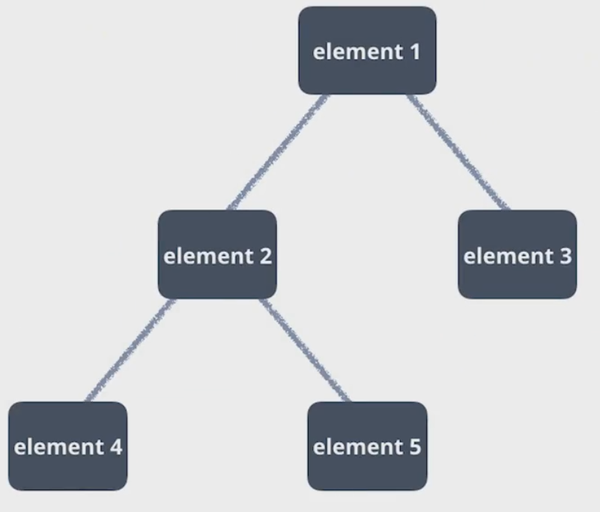
为避免不必要的错误,或许这几句代码是任何html文件必须的:
<!DOCTYPE html> <!--声明>
<html>
<head>
<meta charset=UTF-8> <!--防止出现乱码-->
<title>Hello World!</title> <!--网页总要起个名字噻-->(SEO的关键)
</head>
<body>
</body>
</html> 5.浏览器是如何翻译html文件的?
首先,浏览器根据文档对象模型(Document Object Model:DOM,是规定HTML如何转换成元素树状结构的标准,是浏览器与HTML文件打交道的中间桥梁;否则,每个浏览器按自己的理解表现HTML,同样的文件,渲染出来的网页完全不一致;这也是为什么DOM会出现的原因。(或许,如果当初微软不推出ie,世上只有网景这一款浏览器,就不会有DOM了。)将标签转换成树状结构。然后,将内容按照“文档流”从浏览器的左上角依次向下排列。其次,浏览器根据标签的含义来显示哪个是文本,哪个是图片。(标签将内容包裹起来,就是给内容打上了标记,浏览器阅读到标签的时候,根据标签的含义,就知道这段内容是文本还是图片)
每个标签自产生就决定了自己的展示方式,即display属性。每个标签都有一个天生的display属性值:block(块级元素)inline(行内元素)。区别在于block会独自占一行;inline只有在一行内空间不够时才会换行:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Tree to HTML</title>
<head>
<body>
<h1>即使内容很少,我也会把其他元素挤下去,好让我自己占一行</h1>
<p>我跟h1一样自私,内容这么少,我还是占了一行</p>
<img src="image/1.jpg" alt="love life" width="150" height="150">
<a href="#">我是inline,所以我跟img占了同一行</a>
</body>
</html> 
6.其他
除了以上概念外,HTML字符实体也是需要知道的概念。有一些字符被HTML赋予了特殊的含义,无法在页面正常显示这些字符。如<,HTML中,它就表示标签的开始。那么如何在页面中显示<呢?这时就要用到HTML实体。

发表评论